
The Engineering Reality of Making AI Safe for Kids
Adding AI to a product is easy. Making it actually safe for children is a completely different engineering animal.
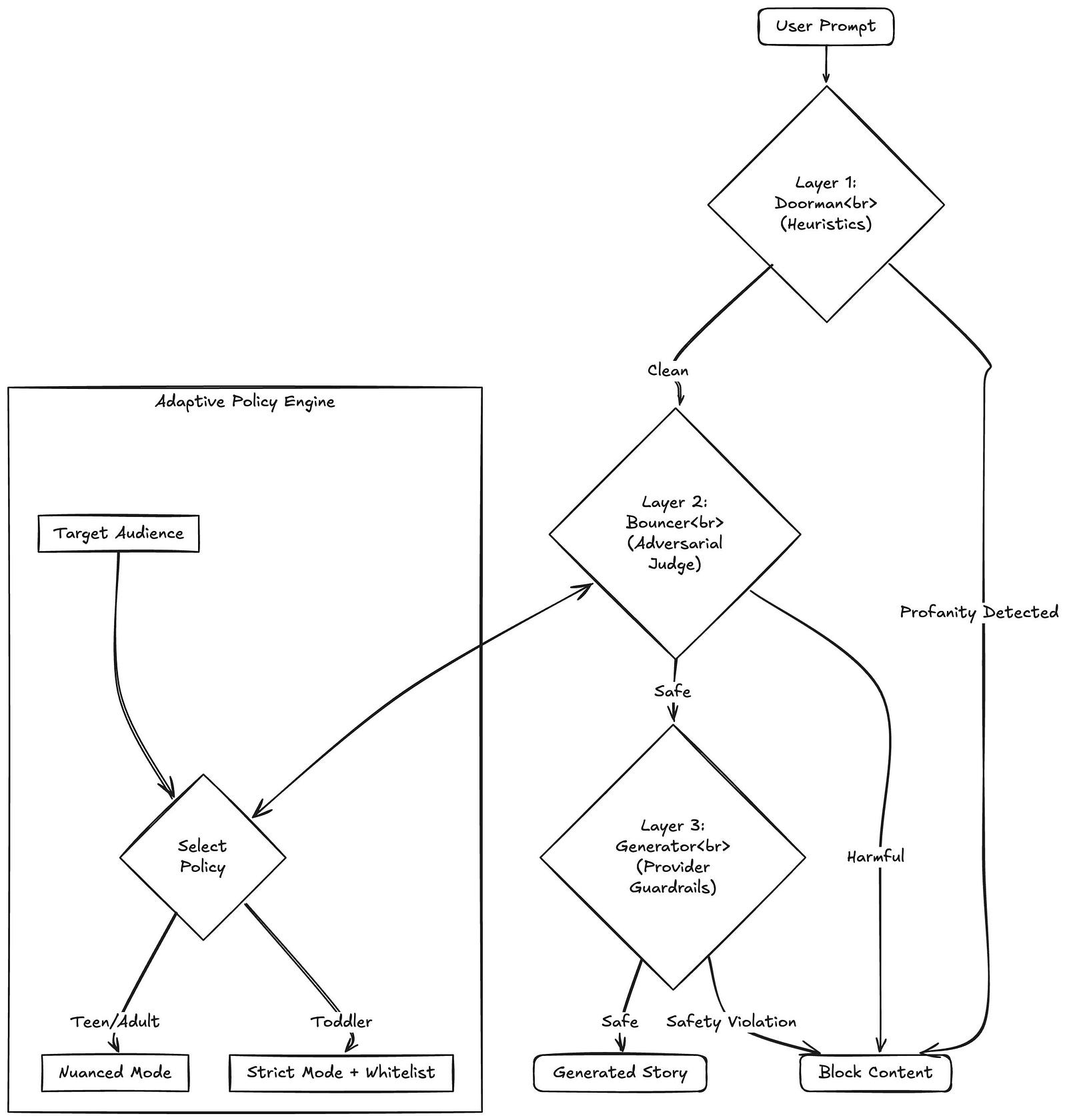
At MintMyStory, we generate custom books for kids. In our world, an AI "hallucination" isn't just a funny bug you can laugh off; it's a failure we simply can't afford. We can't just cross our fingers and hope the AI behaves. We had to build a pipeline that actively filters every prompt and output through three independent layers.
The Problem: AI Wants to be Helpful (To a Fault)
Models like Gemini or GPT-4 are designed to follow instructions. If a kid asks for a "scary battle," the AI’s instinct is to comply and be creative.
The issue is that "helpfulness" often conflicts with safety. We realized early on that we couldn't trust the story-generator to moderate itself. We needed a separate "Judge"—a dedicated model with zero creative intent and a very critical eye.
Our Three-Layer Defense
Every single prompt has to pass through three distinct security gates before a single word of the story is written.
1. The Keyword Filter (Fast & Local)
Before we make any expensive API calls to an AI model, we run a local check. This handles the obvious stuff—slurs, explicit language, and spam.
We also use this layer to scrub personal info. Kids (and sometimes parents) often type real names or home addresses into the story prompt. Our system anonymizes this data immediately so it never reaches the external generative models.
2. The Adversarial Judge (Deep Context)
This is where the real work happens. We use a separate AI model prompted exclusively as a Safety Auditor. Its only job is to act as a skeptic. It looks for nuance that a simple word list misses—things like intent, subtle violence, or inappropriate themes disguised as innocent analogies. Since this model isn't trying to write a story, it doesn't have a "creative bias."
3. The Guardrails (The Final Net)
Finally, even the story generator itself operates under the strictest possible safety settings. This serves as a last line of defense for the output-side. If the AI somehow creates a sentence that feels "off," this layer blocks it before it ever reaches the user's screen.
Choosing the "False Positive" Trade-off
When we first stress-tested this framework, our filters were so aggressive that they blocked about 60% of perfectly innocent story prompts.
We decided that was acceptable. In the world of child-tech, letting something bad through (a "false negative") is a disaster. We would much rather block five harmless stories than let one dangerous one slip through. We've spent months refining the logic to be more accurate, but our "fail-secure" philosophy hasn't changed.
Beyond "Bad Words"
Our safety approach is informed by a couple of core psychological principles:
- UNICEF Guidance: Standard AI safety is built for adults. Children are more susceptible to manipulation, so the safety layers have to be rigid.
- The Eliza Effect: Kids bond with AI very quickly. Safety isn't just about blocking violence; it's about ensuring the AI doesn't act in an emotionally deceptive or authoritative way over the child.
Safety shouldn't be a corporate slogan. By layering these checks into our architecture, we've turned child safety from a hope into an engineered, measurable part of the platform.


